Document Data Transfer (DDT) is a cross-data center data replication platform based on MongoDB.
Background
In the current database ecosystem, most systems support data synchronization across multiple node instances, extending to cross-unit and even cross-data center synchronization. This is crucial for business scenarios, enabling load balancing across multiple data centers in the same city, mutual backups between data centers, and even disaster recovery and multi-active setups across geographically distributed data centers. However, MongoDB's built-in primary-secondary replication has significant limitations for these scenarios. To address this, we developed the MongoShake system, designed for instance-level replication, replication between data centers, and cross-data center replication, meeting disaster recovery and multi-active requirements.
Introduction
DDT is a Java-based data transfer tool developed by Jinmu Information, offering high stability, flexibility, and availability. It supports fast and reliable data migration for tasks like data backup, real-time migration, and disaster recovery, with customizable configuration parameters for different needs. Unlike MongoDB's built-in replication, DDT allows for instance-level, data center-level, and cross-data center synchronization, making it ideal for multi-active and disaster recovery scenarios. It supports data transfer between standalone nodes, replica sets, and sharded clusters, utilizing efficient OPLOG parsing for high-performance real-time synchronization.
MongoDB Versions
Supported Versions: DDT supports MongoDB versions 3.2, 3.4, 3.6, 4.0, 4.4, 5.0, and 6.0.
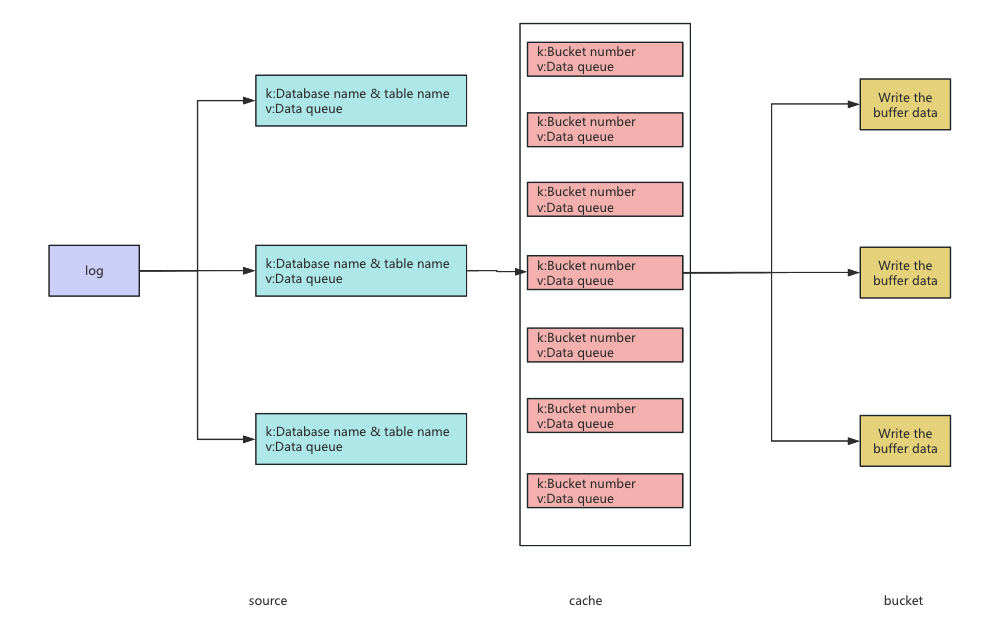
Full Data Backup Between MongoDB Clusters
This mode is ideal for scenarios where you need to create a complete snapshot of the entire database to ensure that all data is preserved, such as before performing major system upgrades or migrations.
Real-Time Data Backup Between MongoDB Clusters
This is suitable for environments that require continuous data protection, such as in high-availability systems where minimizing data loss is critical during system failures.
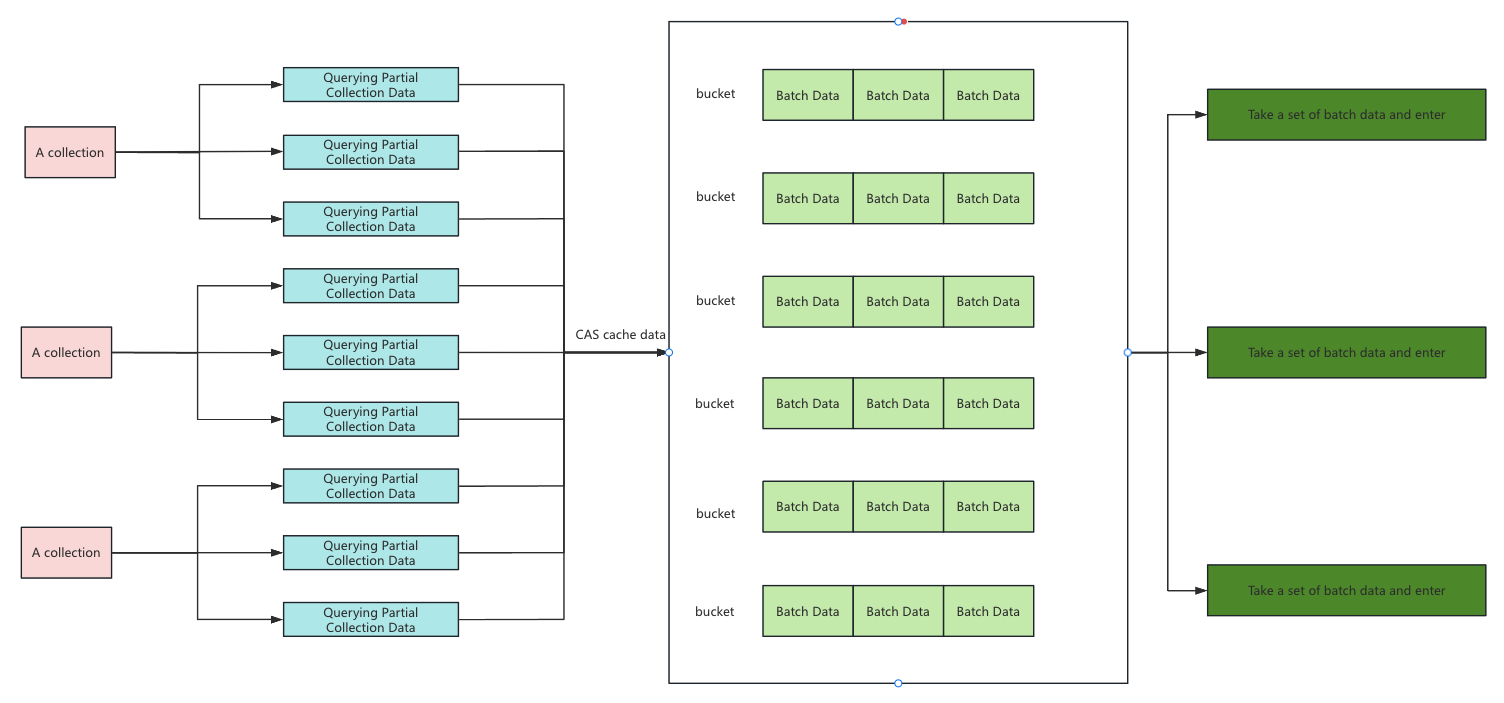
Full + Real-Time Data Backup Between MongoDB Clusters
This mode is useful when you need an initial complete backup followed by real-time updates, such as setting up a disaster recovery site where the initial data load is large, followed by ongoing synchronization.
Full + Incremental Data Backup Between MongoDB Clusters
This mode is appropriate for scenarios where you need to perform a one-time full backup followed by regular incremental backups, such as in environments where data changes frequently, but full backups are too time-consuming or resource-intensive.
DDT offers flexible configuration options to meet various requirements, allowing you to adapt to different application scenarios. The available features include

Print All User Information from the Cluster
Outputs detailed information about all users in the MongoDB cluster, making it easier to manage and audit user permissions and role assignments.

Synchronize Database and Table Schemas
Syncs the database and table structures from the source cluster to the target cluster, ensuring consistency in schema definitions during migration or replication.

Synchronize Database and Table Index Information
Transfers index configurations from the source cluster to the target cluster, ensuring that index structures are consistent to maintain query performance.
Enable Sharding for All Databases
Activates sharding for all databases in the target cluster, optimizing storage and query performance in distributed environments, especially when dealing with large datasets.
Synchronize Shard Keys for Databases and Tables
Syncs the shard keys defined in the source cluster to the target cluster, ensuring consistent data distribution and access paths across both clusters.
Synchronize config.settings Table
Transfers the config.settings table, which contains critical configuration parameters, from the source cluster to the target cluster to maintain consistent cluster configurations.
Pre-split Chunks for Databases and Tables
Pre-splits chunks (data blocks) in the target cluster to optimize data distribution and query performance, particularly in scenarios with large datasets or complex sharding strategies.These features can be combined as needed, for example, 1, 2, 3, 4, 5, 6 or 1, 2, 3, 7. The default configuration is empty.